![[백준 알고리즘][파이썬/Python] 2941번: 크로아티아 알파벳](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbVIixZ%2FbtqCX9AwpSG%2FAAAAAAAAAAAAAAAAAAAAAMqhcFYF7IYI_mKdEQgZKpuw31xw_CXXz1wxiwvJtnBp%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D%252Bup8rtM7%252B6QyCCn9NNJdj21WxoQ%253D)
문제
예전에는 운영체제에서 크로아티아 알파벳을 입력할 수가 없었다. 따라서, 다음과 같이 크로아티아 알파벳을 변경해서 입력했다.
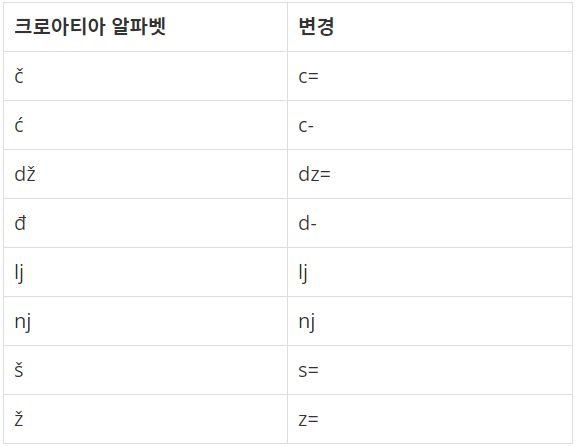
예를 들어, ljes=njak은 크로아티아 알파벳 6개(lj, e, š, nj, a, k)로 이루어져 있다. 단어가 주어졌을 때, 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다. dž는 무조건 하나의 알파벳으로 쓰이고, d와 ž가 분리된 것으로 보지 않는다. lj와 nj도 마찬가지이다. 위 목록에 없는 알파벳은 한 글자씩 센다.
입력
첫째 줄에 최대 100글자의 단어가 주어진다. 알파벳 소문자와 '-', '='로만 이루어져 있다.
단어는 크로아티아 알파벳으로 이루어져 있다. 문제 설명의 표에 나와있는 알파벳은 변경된 형태로 입력된다.
출력
입력으로 주어진 단어가 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력한다.
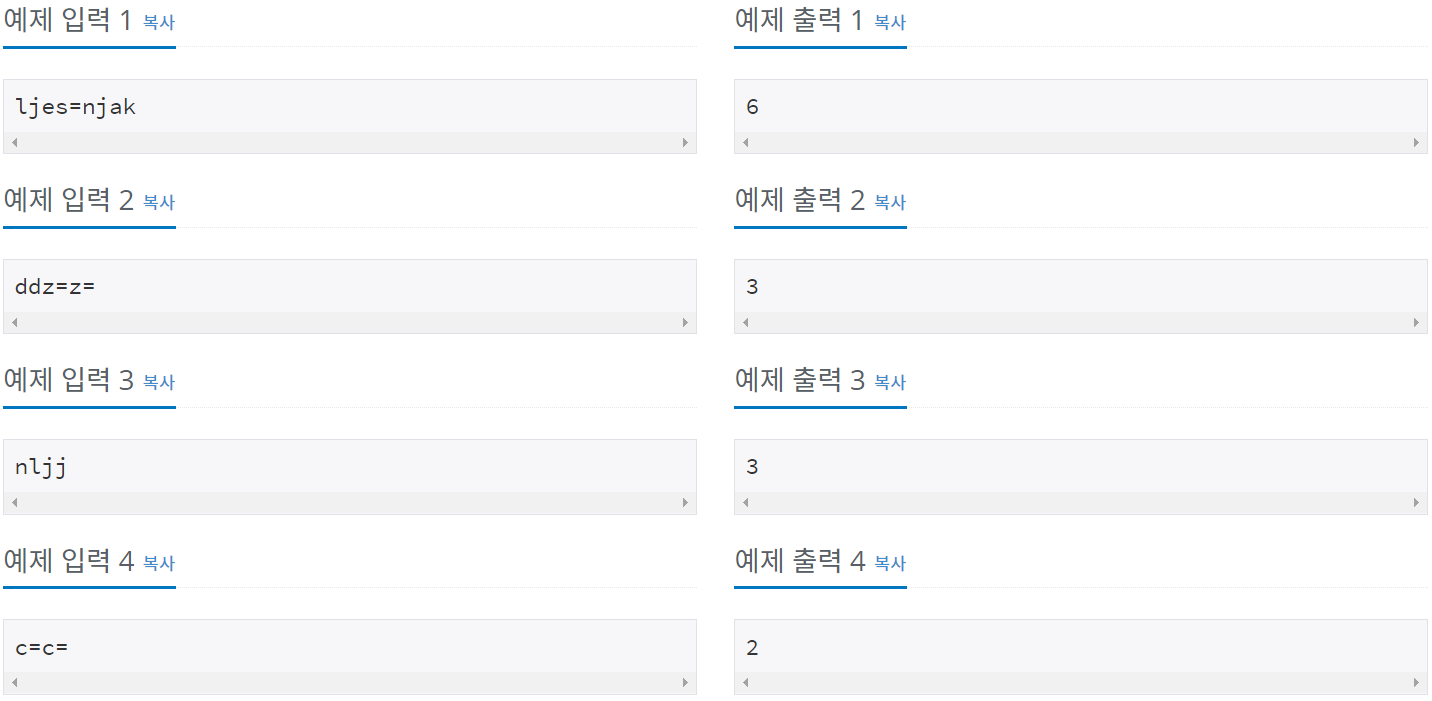
입출력 예
제출 코드
s = input()
lst = ['c=', 'c-', 'dz=', 'd-', 'lj', 'nj', 's=', 'z=']
cnt = 0
for i in lst:
while i in s:
cnt += s.count(i)
s = s.replace(i, '0'*len(i))
print(cnt + len(s) - s.count('0'))이 문제는 은근히 삑사리가 났었다. 길게 말할 건 아니고, 기존의 코드에서는 단순히 5번 라인의 반복문 조건에 만족했을 경우에 s = s[:s.index(i)] + s[s.index(i) + len(i):] 와 같은 식으로 슬라이싱을 하며 cnt를 1씩 증가시켜 나갔었다. 그런데 입력받았던 s에서 특정 부분이 슬라이싱되니 빈 공간을 메우며 슬라이싱된 곳 앞과 뒤가 붙게 될 때 문제가 생겼다.
예제 입력3 같은 경우, 알파벳은 총 'n', 'lj', 'j' 3개가 있는 것인데 lj가 슬라이싱되어 n과 j가 붙으니 'nj'가 되었다. 이는 lst 안에 있는 알파벳이므로 해당 단어도 날아가버리게 된다. 그래서 최종적으로 2가 출력되어 버렸었다.
그래서 replace로 바꿨는데, replace를 오랜만에 쓰니까 또 까먹었던 것이 있다. 해당 문자열 안에서 replace하고자 하는 문자열은 "모두" 바꿔버린다는 것이다. 그래서 count 메서드를 같이 썼다. 최종적으로 s는 변경된 크로아티아 알파벳이었던 자리는 모두 0으로 대체되고, 변경된 크로아티아 알파벳 테이블에 없는 알파벳들만 남게 될 것이다. 이 알파벳들은 문제 설명에서 '위 목록에 없는 알파벳은 한 글자씩 센다.'라고 나와있기 때문에, 이것들의 개수는 문자열 s의 길이에서 '0'의 개수만큼 빼면 쉽게 구할 수 있다.
Source : https://www.acmicpc.net/problem/2941
'PS > 백준' 카테고리의 다른 글
| [백준 알고리즘][파이썬/Python] 2839번: 설탕 배달 (0) | 2020.04.02 |
|---|---|
| [백준 알고리즘][파이썬/Python] 1712번: 손익분기점 (0) | 2020.04.01 |
| [백준 알고리즘][파이썬/Python] 1065번: 한수 (0) | 2020.03.30 |
| [백준 알고리즘][파이썬/Python] 4344번: 평균은 넘겠지 (0) | 2020.03.29 |
| [백준 알고리즘][파이썬/Python] 1157번: 단어 공부 (0) | 2020.03.28 |